 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallax: Parameterized Local Linear Attention for Language Modeling
May 27, 2026Large Language Models (LLMs) have become the central paradigm in artificial intelligence, yet the core computational primitive of attention has remained structurally unchanged. Local Linear Attention (LLA) is an attention mechanism derived from nonparametric statistics in the test-time regression framework. In contrast to prior research on efficient attention variants, LLA upgrades the local constant estimate in softmax attention to a local linear estimate, yielding provably superior bias-variance tradeoffs for associative memory. However, LLA has not been scaled in LLM pretraining due to computational and numerical stability concerns. We introduce Parallax, a parameterized Local Linear Attention that is scalable for LLMs. Parallax eliminates the numerical solver in LLA and learns an extra query-like projector that probes the KV covariance. We place Parallax within a family of attention mechanisms connected by the bandwidth, the probe construction and the affine structure. We propose a hardware-aware algorithm that increases the arithmetic intensity over FlashAttention, shifting attention into a more compute bound regime. Our prototype decode kernel matches or outperforms FlashAttention 2/3 across diverse batch sizes and context lengths. We pretrain Parallax at 0.6B and 1.7B scales and find consistent perplexity improvements throughout pretraining with gains that transfer to downstream benchmarks. The advantage persists under both parameter-matched and compute-matched controls, demonstrating a Pareto improvement. We perform careful pretraining ablations and identify a novel phenomenon whereby Muon unlocks the capacity of Parallax. To our knowledge, this is the first empirical demonstration of strong architecture-optimizer codesign for attention mechanisms in the architecture research literature.
PreFT: Prefill-only finetuning for efficient inference
May 14, 2026Large language models can now be personalised efficiently at scale using parameter efficient finetuning methods (PEFTs), but serving user-specific PEFTs harms throughput, even with specialised kernels and memory management techniques. This is because, theoretically and empirically, a mismatch exists between prefill (processing a large number of tokens at once) and decode (generating a single token autoregressively): the latter has far lower throughput when serving multiple adapters. Rather than optimising performance relative to parameter count, for efficient multi-adapter serving, we instead ought to optimise performance relative to serving throughput. We therefore propose PreFT (Prefill-only Finetuning), wherein we only apply the adapter to prefill tokens and discard it afterwards. PreFT significantly increases throughput with minimal effect on performance. We develop and release an efficient implementation of two prefill-only PEFTs, LoRA and ReFT, on the vLLM inference engine. We first show that serving multi-user PreFTs is more efficient than traditional PEFTs ($1.9\times$ the throughput when serving $512$ adapters on Llama 3.1 70B). Then, we compare the performance of prefill-only vs. all-token adapters on a variety of supervised finetuning and reinforcement learning tasks with LMs at varying scales. On SFT, we observe that the evaluation loss of PreFTs is higher than PEFTs, but can be compensated by increasing rank with nearly no reduction in throughput. On RL, we consistently find that PreFTs approach parity with standard PEFTs. Together, this work validates prefill-only adaptation of LLMs as a more favourable accuracy-throughput tradeoff than existing PEFTs for personalised serving.
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Apr 01, 2024The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops discovered that such loops can lead to model collapse, a phenomenon where performance progressively degrades with each model-fitting iteration until the latest model becomes useless. However, several recent papers studying model collapse assumed that new data replace old data over time rather than assuming data accumulate over time. In this paper, we compare these two settings and show that accumulating data prevents model collapse. We begin by studying an analytically tractable setup in which a sequence of linear models are fit to the previous models' predictions. Previous work showed if data are replaced, the test error increases linearly with the number of model-fitting iterations; we extend this result by proving that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations. We next empirically test whether accumulating data similarly prevents model collapse by pretraining sequences of language models on text corpora. We confirm that replacing data does indeed cause model collapse, then demonstrate that accumulating data prevents model collapse; these results hold across a range of model sizes, architectures and hyperparameters. We further show that similar results hold for other deep generative models on real data: diffusion models for molecule generation and variational autoencoders for image generation. Our work provides consistent theoretical and empirical evidence that data accumulation mitigates model collapse.
Bridging Associative Memory and Probabilistic Modeling
Feb 15, 2024



Associative memory and probabilistic modeling are two fundamental topics in artificial intelligence. The first studies recurrent neural networks designed to denoise, complete and retrieve data, whereas the second studies learning and sampling from probability distributions. Based on the observation that associative memory's energy functions can be seen as probabilistic modeling's negative log likelihoods, we build a bridge between the two that enables useful flow of ideas in both directions. We showcase four examples: First, we propose new energy-based models that flexibly adapt their energy functions to new in-context datasets, an approach we term \textit{in-context learning of energy functions}. Second, we propose two new associative memory models: one that dynamically creates new memories as necessitated by the training data using Bayesian nonparametrics, and another that explicitly computes proportional memory assignments using the evidence lower bound. Third, using tools from associative memory, we analytically and numerically characterize the memory capacity of Gaussian kernel density estimators, a widespread tool in probababilistic modeling. Fourth, we study a widespread implementation choice in transformers -- normalization followed by self attention -- to show it performs clustering on the hypersphere. Altogether, this work urges further exchange of useful ideas between these two continents of artificial intelligence.
Deceptive Alignment Monitoring
Jul 26, 2023As the capabilities of large machine learning models continue to grow, and as the autonomy afforded to such models continues to expand, the spectre of a new adversary looms: the models themselves. The threat that a model might behave in a seemingly reasonable manner, while secretly and subtly modifying its behavior for ulterior reasons is often referred to as deceptive alignment in the AI Safety & Alignment communities. Consequently, we call this new direction Deceptive Alignment Monitoring. In this work, we identify emerging directions in diverse machine learning subfields that we believe will become increasingly important and intertwined in the near future for deceptive alignment monitoring, and we argue that advances in these fields present both long-term challenges and new research opportunities. We conclude by advocating for greater involvement by the adversarial machine learning community in these emerging directions.
FACADE: A Framework for Adversarial Circuit Anomaly Detection and Evaluation
Jul 20, 2023
We present FACADE, a novel probabilistic and geometric framework designed for unsupervised mechanistic anomaly detection in deep neural networks. Its primary goal is advancing the understanding and mitigation of adversarial attacks. FACADE aims to generate probabilistic distributions over circuits, which provide critical insights to their contribution to changes in the manifold properties of pseudo-classes, or high-dimensional modes in activation space, yielding a powerful tool for uncovering and combating adversarial attacks. Our approach seeks to improve model robustness, enhance scalable model oversight, and demonstrates promising applications in real-world deployment settings.
The impact of varying electrical stimulation parameters on neuromuscular response
Dec 03, 2021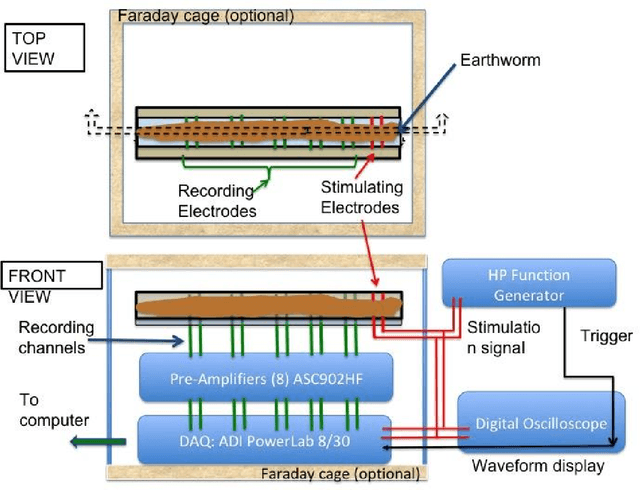
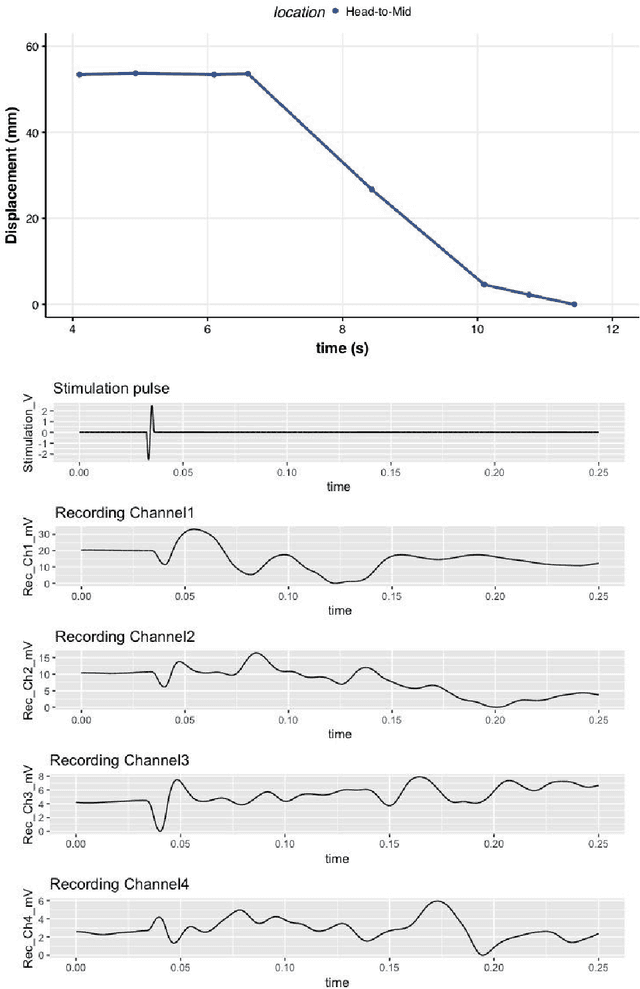
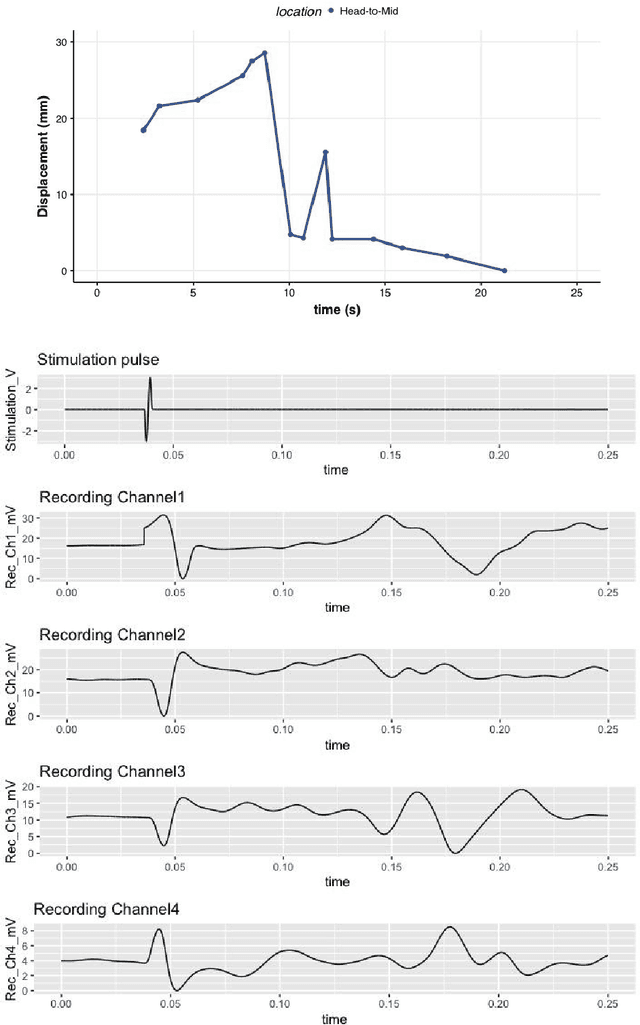
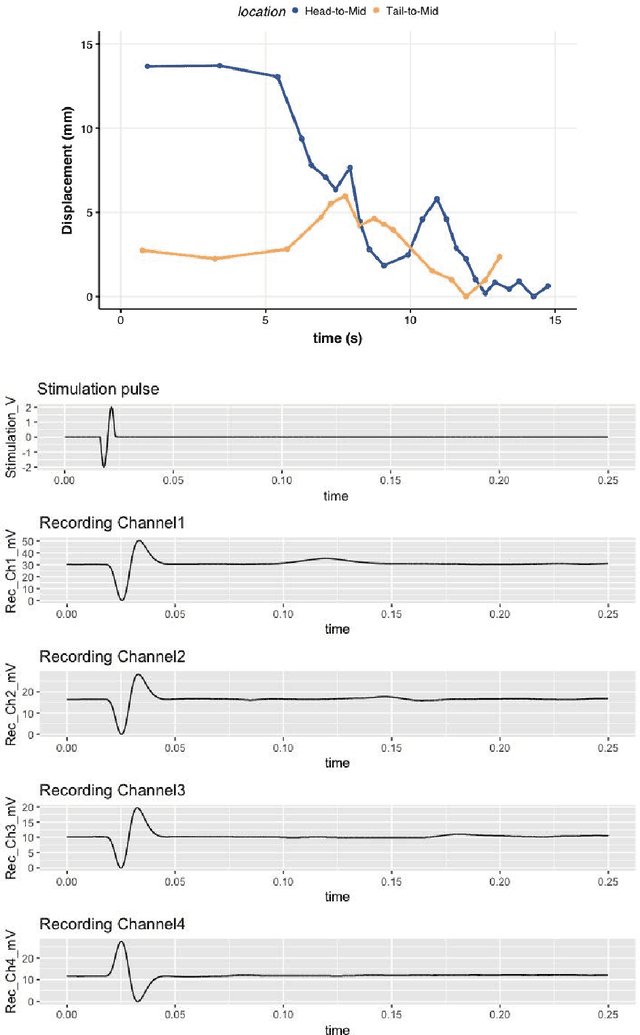
High density neurostimulation systems are coming to market to help spinal cord injury patients by stimulating and recording neuromuscular function. However, the parameter space that these systems have to explore is exceedingly large, and would need an artificial intelligence (AI) system to optimize. We need a platform that will allow us to determine the optimal parameter space for these systems. Our project aims to build a platform for mapping and controlling neuromuscular activity, as a high-throughput testbed for implementing and testing closed-loop neuromuscular activity. This abstract presents the first phase (the mapping phase) of building that testbed by combining multi-electrode stimulation/recording with visual motion-tracking. A 3D-printed rectangular raceway was used with 4 pairs of differential recording electrodes, and two stimulation electrodes embedded in the raceway bed. Non-anesthetized earthworms were placed on the raceway with their head section on the stimulating electrodes. Bipolar sinusoidal stimulation pulses of a range of voltages (2 to 6Vp-p), pulse durations (2 ms to 6.7 ms), and a burst rate of 1 pulse per second were applied, and action potentials and physical motion were recorded and analyzed. Action potentials were found to correlate with expansion/contraction displacements of worm segments, and voltage increases were shown to increase action potential propagation amplitude. Using the multiple electrode recording allowed us to capture the wave propagation of action potential pulse over the length of the worm. Feasibility of a platform to simultaneously monitor action potentials and motion of earthworms with real-time mapping was demonstrated.